x86 Assembly for Beginners
This was supposed to be a series of posts, but as it stands today – “the second post is still awaited”.
Let’s Go!
Let us start with a simple CPP snippet. The function foo takes in two parameters and calculates some formula using the parameters and the globals. Note that u is not used. It has been deliberately left this way. This will help us visit it again as we make way for compiler optimisations later!
For this post and hope for the entire series, I will be using clang-LLVM for compilation. Most of the flags should just be fine with GCC too, none the less. My machine has an x86 64-bit architecture.
Level O: Program Memory Layout
Where to start this? Understanding the internal memory layout of a program is important. Take the above code for instance. Where will the instructions reside? Are A and B, any different from local variables u and w? What if dynamically allocate an int in the foo function? All these questions are answered using the program memory layout. Let’s have a look.
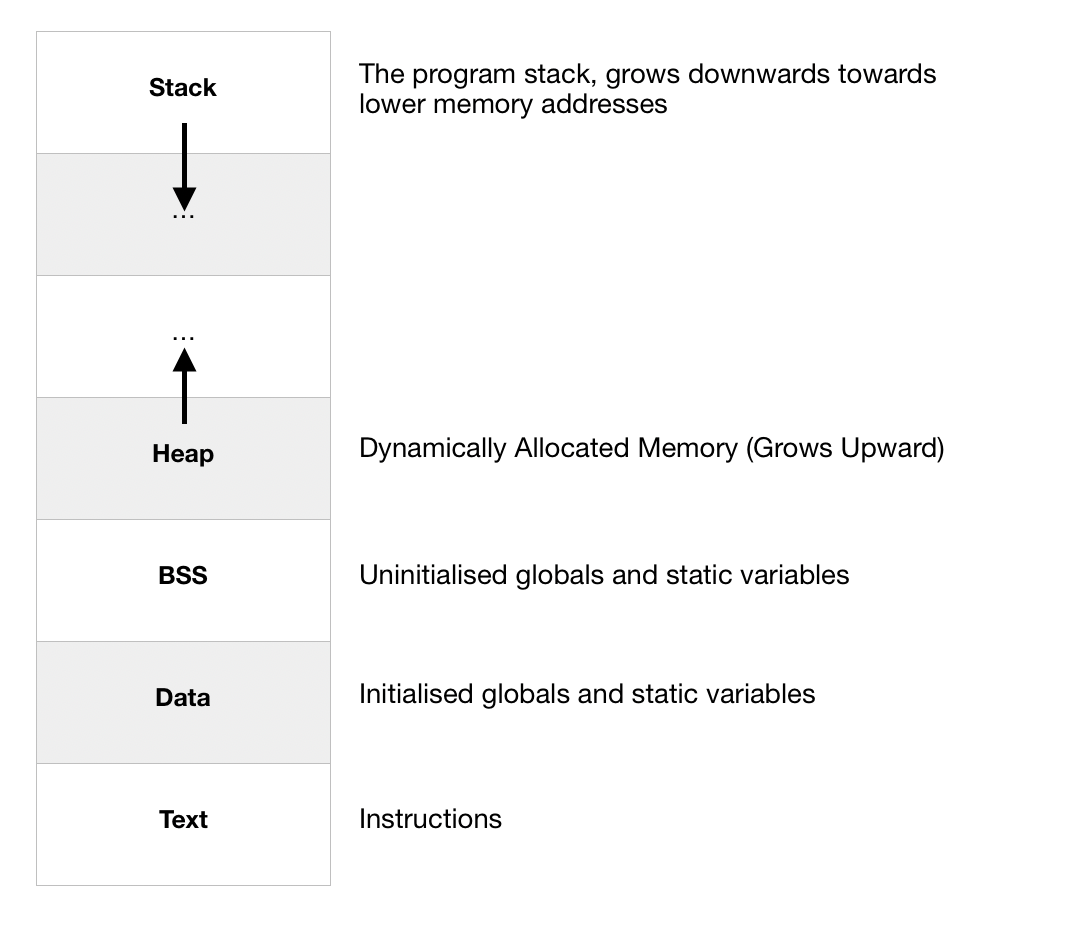 |
Here is what should be happening roughly. The code itself (the instructions) will reside in the text section. Clearly, its size is fixed and doesn’t change during execution. The globals and the static variables will be going into either BSS or the data sections. In this case, A and B both will reside in the data section. We will look at the BSS (Binary Service Set) section later in some post. For foo to be executed, we expect to have a caller. That caller puts the arguments x and y on the stack and calls foo, which expands the stack and performs its local operations finally returning w. The control goes back to the caller and foo’s stack frame is removed. In case foo is the main, the caller is the C/C++ runtime environment.
For completeness, let’s consider this. What if we have these lines in foo after line 8:
int* alpha = &u;
int* beta = new int;
// do something
delete beta;
Here alpha is a pointer to u. We know u resides on the stack. But where will alpha reside? How is this different from the second case? Convince yourself that alpha and beta both will reside on the stack. In the first case, we have a pointer on the stack alpha, pointing to memory again on the stack u. While in the second case, we have a pointer on the stack beta, which points to a memory which is dynamically allocated (i.e. the memory being pointed to is on the heap).
First look at assembly
Compiling with clang++ -S start.cpp -O0 -o start_O0.s, here is what we get. The -S flag allows us to stop the compilation at the point where the assembly is generated. Without it, we get straight to the object code (the executable). -O0 is to disable any optimisations done by the compiler. For starters, it is good to see the unoptimised assembly as it is easier to comprehend. More here.
The first thing to notice are the sections: the text section and the data section in the above assembly.
About Registers
Assembly, among other things, involves instructions (understood by x86) and assembler directives. The directives can be considered as instructions to the assembler to perform things in different ways - usually for tasks like reserving storage and control-related functions. To differentiate between directives and instructions, directives always start with a period. For example, .section, .globl etc. are all directives, whereas addl, movl etc. are instructions.
The instructions involve registers. There are considerable differences between registers in 32 bit systems vs 64 bit systems. Classically, x86 has had 8 general-purpose registers (GPRs), the 64-bit x86 further added 8 more GPRs. (Info)
Each of the GPRs can be used in 64, 32, 16 and 8 bit modes. So all of %rax, %eax, %ax, %al and %ah are actually referring to the same register (different number and position of bytes in it) as described in this figure, or maybe not. Similar things happen for the other GPRs, see the info.

‘bar’ calls ‘foo’, what happens?
Now, let us look at two of these registers - Stack Pointer (SP) and Base Pointer (BP). As expected, they can be used as %rsp, %esp, %rbp, %ebp etc. SP always points to the top of the stack (the lowest address), while BP points to the base of the current frame. To have a more clear idea, we need to understand what happens when a function is called.
Let’s say function foo is called by some function bar. What all is required to be known by foo? The first things are the values of parameters being passed.
We know that instructions are in their section (memory). We use an Instruction Pointer (IP) to locate the current instruction to execute. Once the instruction has been successfully executed, the IP is incremented to point to the next instruction in line. In case of a function call, the instruction pointer is modified to point to the first instruction of the called function. Note that these instructions may be elsewhere, and the called function would eventually need to know how to fix the IP back after it has finished executing so that the caller’s execution can continue right from the next instruction after the call.
Therefore, in addition to the parameters which may or may not be required (based on the function’s definition), we absolutely need a return address to jump back to.
So when foo is called, we say that its frame is being pushed to the stack. Its frame is basically the part of stack it is going to use. Before jumping to foo’s instructions, bar pushes the two parameters and the return address to the stack. This moves the stack’s top and so the stack pointer is updated. At this point, the value of stack pointer is the frame/base pointer. foo may further increase the stack size by allocating space for its locals on the stack. These addresses can be accessed using suitable offsets on the base pointer.
We may not need base pointer at times. We can just be fine by offsetting from the stack pointer. This gives rise to omit-frame-pointer optimisation. This speeds up function calls as the base pointer need not be set. Further, it also frees one register for the use which would have been, otherwise, populated by the base pointer.
Push n’ Pop
What are the push and pop instructions that we see in the assembly? We have only a fixed number of registers. Data needs to be on these registers for instructions to act on them. Push and pop allow us to push contents of any register to the stack and then pop them back when needed. In foo’s assembly, just when we are about to save the new base pointer, we should also remember that we need to save bar’s (the caller’s) base pointer on the stack so that we can set it back when returning. This is achieved by pushing the base pointer onto the stack. This effectively just writes the value of the base pointer to the current top of the stack. This is followed by foo’s execution which may result in more modifications to the stack. But eventually, right when we are ready to return from foo we are again at the same state as we were at the beginning of its execution. This means we can once again set the base pointer to its previous value (bar’s base) by popping from the stack. This moves the value from the top of the stack to the said register.